Posts
-
Being in the Driver's Seat of the Product Roadmap
One of the key attributes for a Product Manager is the ability to take the driver’s seat in developing a product roadmap. These are slides and notes from a presentation I did as PM for Wikipedia Mobile, which are an example of my taking ownership of a product roadmap.
-
Wikipedia Event Logging Analysis
This comes from an interview task for a data analyst position at Wikipedia. I thought it would be good practice for working with SQL, product analysis, and data visualization/reporting.

-
Kaggle Tensorflow 2.0 Natural Question Answer
This notebook pertains to the Kaggle Natural Question and Answer competition. I’m late to the competition (there are 6 days left in a 3 month compeition). But the competition was interesting. I ended up ranking 152/1240 = 12%. I spent my time trying to:
- Understand the data and the problem, since I am particularly interested in NLP problems this competition attracted me and I know that by understanding the problem and the data I can be better prepared for future NLP problems
- Apply the Google baseline model as well as possible (Google published a model that had results that would have been good enough to rank in around the top 10% so I knew this would be a reasonable path to good results in 6 days)
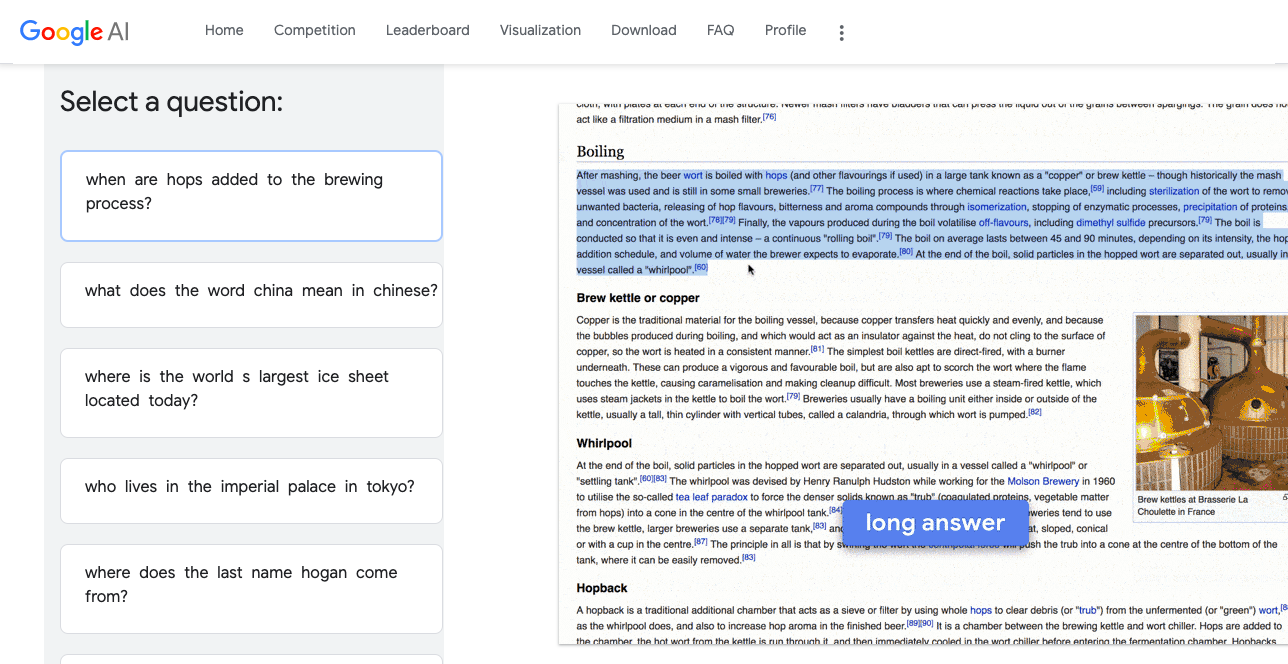 source: https://ai.google.com/research/NaturalQuestions/visualization
source: https://ai.google.com/research/NaturalQuestions/visualization
-
Neural Machine Translation
This project translates text from German to English. It uses LSTMs, it is trained and tested on a small corpus.
-
Photo Captioning with VGG and LSTMs
This project is to generate captions on images. This problem usually seen as an example of the power of deep learning because it uses deeplearning to run classification on the images and to generate texts.
 Caption generated: “black dog is running through the water.” Photo by bambe1964, some rights reserved.
Caption generated: “black dog is running through the water.” Photo by bambe1964, some rights reserved. -
On-board users well
Most products need good documentation - FAQs, “how to”s, explanatory documents. But if your product is heavily reliant on documentation you could stand to improve the usability of your product. New users should especially be saved from reading lots of documentation. Editing Wikipedia is a fairly complex process, it requires learning certain mechanics and a new culture. Bringing new users on board (on-boarding) means thinking through what information to present when, how to be understood, and how to engage the user.
 me presenting at a monthly metrics meeting
me presenting at a monthly metrics meeting -
Working with Designers
At the Wikimedia Foundation I got to work with some great designers. Two projects in particular stick out to me:
1- A typography refresh
2- Design changes to humanize Wikipedia
-
Gaining Insight through Qualitative and Quantitative Analysis
At the Wikimedia Foundation we had a major success in my department during my time there. For years the most pressing issue was a decline in the number of active editors, people who edited 5 or more times in a month. As many of you know, Wikipedia is crowdsourced, so it is these editors who create the articles on Wikipedia. Since the end of 2007 that number had been going down.

-
What it takes to Define a New Space
My first startup, AppCentral, stumbled upon an issue that no one had solved at the time. Companies wanted to use mobile apps to improve their businesses but they didn’t know how to: distribute, secure, and administer their applications. In short, they didn’t know how to manage their applications.
-
Recognizing Opportunities (and pivoting)
My first startup was a great experience, partially because I learned a lot. When I joined the company, it was called Ondeego. It was 2008, we were a mobile startup before the iPhone had an App Store.
-
Lyrics Generator with Simple Web App

Web App Demo: Lyrics Generation
Enter text like
sing with meorhow much do I love you, and the app will ‘sing back’ with Beatles-like lyrics.Note: sometimes the model may get into a repetitive loop, its not perfect :-)
-
Sentiment Analysis with Multi-Channel CNNs
This project performs sentiment analysis with word embeddings and CNNs, but improves the performance by training 3 CNNs with different kernels.
-
Sentiment Analysis with Word Embeddings and CNNs
Use word embeddings to encode text and a single layer convolutional networks to perform classification.
-
Image Classifiers with Tensorflow 2.0
This project explores Tensorflow 2.0 using Keras to build image classifiers in two different ways.
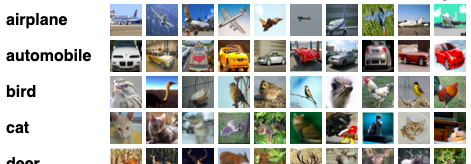 Sample images from: CIFAR-10 dataset
Sample images from: CIFAR-10 dataset -
Sentiment Analysis with Bag of Words and a Multilayer Perceptron
Use TF Keras to build and test various MLPs on Movie Sentiment Analysis. Use NLTK to clean data.
-
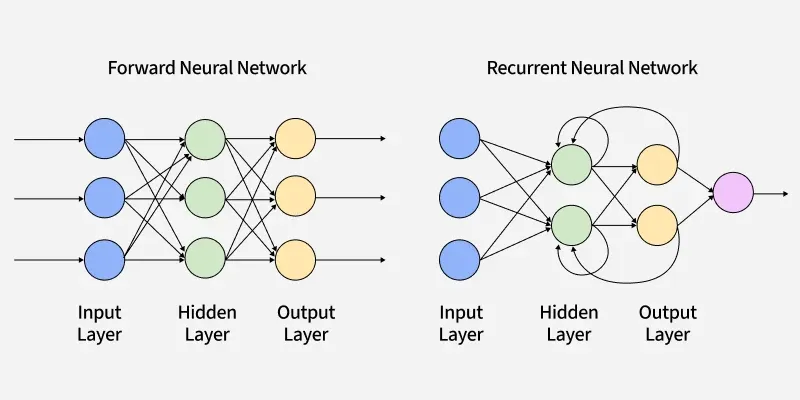
Implementing Recurrent Neural Network
This is an implementation of a basic RNN (not bi-directional, not an LSTM) from scratch (using only numpy). This program will do character level text prediction.
-
Implementing Convolutional Neural Network
This notebook is an implementation of a convolutional neural network with forward and back propogation using no machine learning libraries. I will implement one convolution layer, one activation layer, one pooling layer, one fully connected layer producing logits, and then a softmax.

-
Movie Recommender
This project uses item based collaborative filtering to make movie recommendations. Because this project was unique I implemented cross-validation and hyperparameter tuning from scratch, and defined project specific metrics.
-
Build a Neural Net
This is an implementation of a simple neural net on toy data using only numpy for linear algebra. There is one hidden layer of neurons and thus two layers of synapses. It uses backpropogation to train the synapse weights. Thanks to Siraj Raval who showed this simple implementation on YouTube.
-
NCAA Basketball Game Situation
This is a SQL query on the public BigQuery Database located here. It allows you to find the number of games since 2013 where the game situation (game differential and time elapsed in the game) defined in the WHERE statement of the main query (found after the common table expressions) has happened. It also tells you how often the home team won in those games.
-
Implementing Perceptron
This is an implementation of what is generally considered the most simple neural network (one neuron), the perceptron, with a gradient descent method for finding the weights for the synapses to that single neuron.
-
NBA Win Percentage
On ESPN if you watch the gamecast of a game they give an updated win percentage as the game progresses. We are going to produce a similar prediction, calculating win percentage for a home team given point differential, quarter, and time left in the game.
-
Implementing k-Nearest Neighbors
This is an implementation of k_Nearest neighbors using only the most basic python libraries. This algorithm takes make predictions by looking at a set of data points that is most similar, called neighbors, and looking at a number of them (k is the variable in the algorithm that specifies the number of neighbors we will look at).
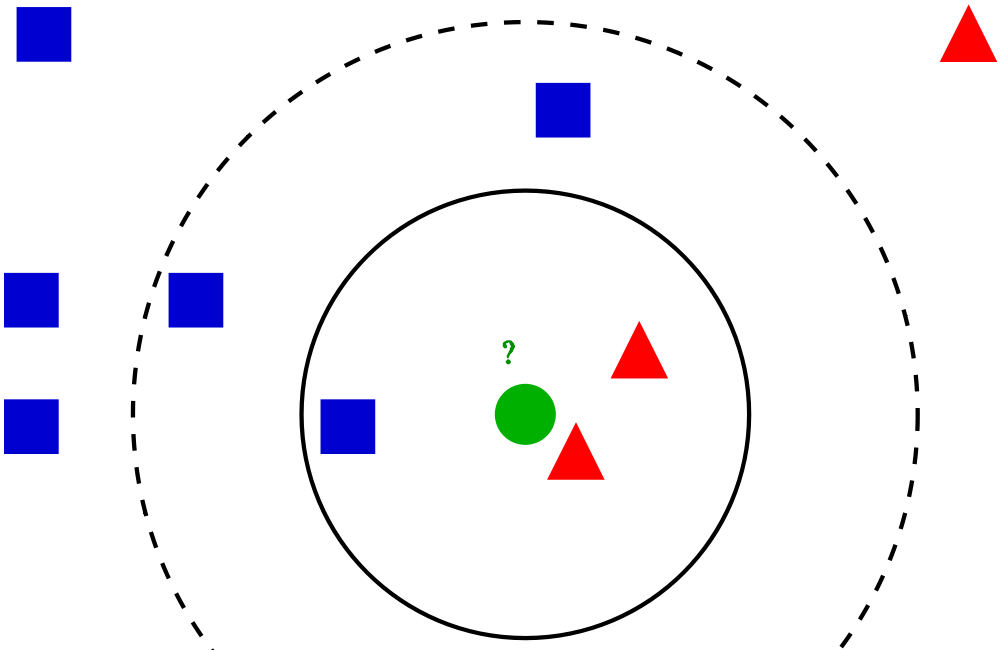
-
Breast Cancer Remission Classification
I will be analyzing a dataset about Breast Cancer remission. The target variable is predicting remission, so we will be performing binary classification. The data is categorical in nature.
-
Implementing Ordinary Least Squares Linear Regression
Linear regression is an approach to modeling where the prediction is a linear combination of some model parameters and the input variables. In this notebook I implement two algorithms for linear regression: Simple Linear Regression and a Gradient Descent Algorithm for Ordinary Least Squares.
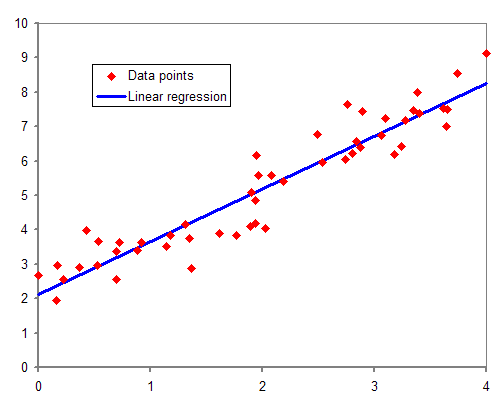
-
Wine Quality Regression
Performing regression and binary classification on Wine Quality Databases in the UCI repository. This is a supervised learning project since there is a training variable.
-
Enron Anomaly Detection using Neural Network Analysis
In this project I am replicating analysis from a research paper found below. This project looks at the activity of a social network as activity in a neural network. Then it attempts to look at “memories” inside of that network and treat the most prominent memories in that network as anomalies in the activity of that social network.
 Photographer: James Nielsen/Getty Images
Photographer: James Nielsen/Getty Images -
Naive-Bayes Implementation
This is an implementation of a Gaussian Naive-Bayes using only numpy using toy data. I follow this guide and use scikit learn for accuracy scoring and I later compare my implementation to the scikit-learn implementation.
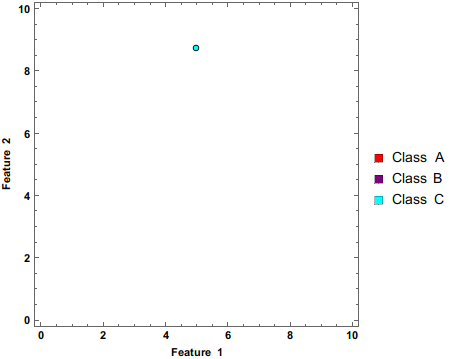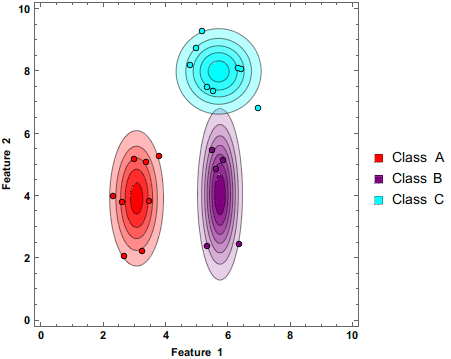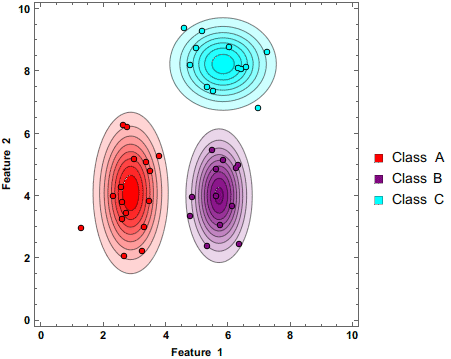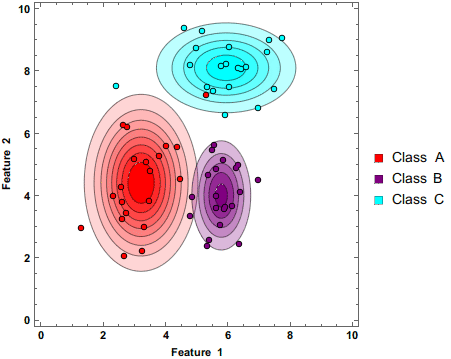
-
Analyzing Twitter Feeds of Politicians
I will use the Twitter API to import tweets related to a user or a hashtag. Then looking at the most common terms for a user I will:
1- Find the most important terms. The way I will do this is by looking at a person’s tweet as a network of interrelated words. If the words occur in a tweet together I’ll consider them interrelated. Then I’ll use mathematical analysis of this network to tell me which words are the most important. Mathematically this kind of analysis on networks is done by calculating Centrality.
2- Perform Sentiment Analysis on the terms, looking for what they speak positively or negatively about.
-
IMDB 5000 Revenue Regression
This project applies Machine Learning to an IMDB database of 5000 movies. The goal is to predict the revenue of movies based on some metadata that has been recorded for the movies including: number of ratings, IMDB ratings, social media stats, the director, the genre. Using this data, ensemble decision trees were able to produce reasonable results, predicting movie revenue to within $24M, but short of the win condition established at the start of the project.




