Sentiment Analysis with Multi-Channel CNNs
This project performs sentiment analysis with word embeddings and CNNs, but improves the performance by training 3 CNNs with different kernels.
The text corpus used is movie reviews. Stanford’s preprepared GloVe database will be used to seed our word embeddings. I’ll try three different models:
1) one without pretrained embeddings
2) one with pretrained embeddings and learning on top of it
3) one with pretrained embeddings and no learning on top
Win condition: >87% accuracy on test split (87% is the upper bound for SVM and other traditional ML techniques on this data, see: http://www.cs.cornell.edu/home/llee/papers/pang-lee-stars.pdf
Attributions: machinelearningmastery.com DL for NLP book
polarity dataset v2.0 ( 3.0Mb) (includes README v2.0): 1000 positive and 1000 negative processed reviews. Introduced in Pang/Lee ACL 2004. Released June 2004.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.
Import Libraries
from os import listdir
import datetime
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import tensorflow.keras as tk
%load_ext tensorboard
import nltk
from nltk.corpus import stopwords
from collections import Counter
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Conv1D, MaxPooling1D, Flatten, Input, Dropout, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
from sklearn.metrics import classification_report
Data Engineering
root_dir = 'review_polarity/txt_sentoken/'
neg_train_dir = root_dir + 'neg_train'
neg_test_dir = root_dir + 'neg_test'
pos_train_dir = root_dir + 'pos_train'
pos_test_dir = root_dir + 'pos_test'
Data cleaning function
def load_doc(filename):
file = open(filename, 'r')
text = file.read()
file.close()
return text
def clean_doc(text):
words = nltk.word_tokenize(text)
alpha_words = [w for w in words if w.isalpha()]
stop_words = set(stopwords.words('english'))
relevant_words = [w for w in alpha_words if w not in stop_words]
filtered_words = [w for w in relevant_words if len(w)>1]
return filtered_words
Build a vocabulary with the training data
def add_doc_to_vocab(filename, vocab):
doc = load_doc(filename)
tokens = clean_doc(doc)
vocab.update(tokens)
def process_docs_to_vocab(directory, vocab):
i=0
for filename in listdir(directory):
if filename.startswith('cv'):
path = directory + '/' + filename
add_doc_to_vocab(path, vocab)
i+=1
print(f'Processed {i} docs.')
return vocab
vocab = Counter()
process_docs_to_vocab(pos_train_dir, vocab)
process_docs_to_vocab(neg_train_dir, vocab)
print(len(vocab))
Processed 900 docs.
Processed 900 docs.
36388
def filter_vocab(vocab, min_occurrences=5):
tokens = [k for k, c in vocab.items() if c >= min_occurrences]
print(len(tokens))
return tokens
filtered_vocab = filter_vocab(vocab, 2)
23548
def save_list(tokens, filename):
if type(tokens[0]) != str:
tokens = str(tokens)
data = '\n'.join(tokens)
file = open(filename, 'w')
file.write(data)
file.close()
save_list(filtered_vocab, 'vocab.txt')
Now use our vocabulary to process our data
vocab_set = set(load_doc('vocab.txt').split())
print(len(vocab_set))
23548
def doc_to_line(filename, vocab):
doc = load_doc(filename)
tokens = clean_doc(doc)
vocab_tokens = [w for w in tokens if w in vocab_set]
return ' '.join(vocab_tokens)
def process_docs_to_lines(directory, vocab):
lines = list()
for filename in listdir(directory):
if filename.startswith('cv'):
path = directory + '/' + filename
line = doc_to_line(path, vocab)
lines.append(line)
return lines
neg_train = process_docs_to_lines(neg_train_dir, vocab_set)
pos_train = process_docs_to_lines(pos_train_dir, vocab_set)
neg_test = process_docs_to_lines(neg_test_dir, vocab_set)
pos_test = process_docs_to_lines(pos_test_dir, vocab_set)
trainX, trainY = neg_train+pos_train, [0]*len(neg_train)+[1]*len(pos_train)
testX, testY = neg_test+pos_test, [0]*len(neg_test)+[1]*len(pos_test)
print(len(trainX), len(trainY))
print(len(testX), len(testY))
1800 1800
200 200
processed = {}
processed['trainX'] = trainX
processed['trainY'] = trainY
processed['testX'] = testX
processed['testY'] = testY
Next the data will be transformed to be input into a word embedding matrix and deep learning algorithms.
# initiate tokenizer and fit to the training data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(trainX)
# encode and pad the sequences
trainX = processed['trainX']
max_length = max([len(doc.split()) for doc in trainX])
trainX = tokenizer.texts_to_sequences(trainX)
trainX = pad_sequences(trainX, maxlen=max_length, padding='post')
testX = processed['testX']
testX = tokenizer.texts_to_sequences(testX)
testX = pad_sequences(testX, maxlen=max_length, padding='post')
trainY, testY = processed['trainY'], processed['testY']
trainY, testY = np.array(trainY), np.array(testY)
transformed = {}
transformed['trainX'] = trainX
transformed['trainY'] = trainY
transformed['testX'] = testX
transformed['testY'] = testY
vocab_size = len(tokenizer.word_index)+1
print(max_length, vocab_size)
1289 23549
Build Models
# first channel kernel of 4
input1 = Input(shape=(max_length,))
embedding1 = Embedding(vocab_size, 100)(input1)
conv1 = Conv1D(32, 4, activation = 'relu')(embedding1)
drop1 = Dropout(.5)(conv1)
pool1 = MaxPooling1D()(drop1)
flat1 = Flatten()(pool1)
# second channel with kernel of 6
input2 = Input(shape=(max_length,))
embedding2 = Embedding(vocab_size, 100)(input2)
conv2 = Conv1D(32, 6, activation = 'relu')(embedding2)
drop2 = Dropout(.5)(conv2)
pool2 = MaxPooling1D()(drop2)
flat2 = Flatten()(pool2)
# third channel
input3 = Input(shape=(max_length,))
embedding3 = Embedding(vocab_size, 100)(input3)
conv3 = Conv1D(32, 8, activation = 'relu')(embedding3)
drop3 = Dropout(.5)(conv3)
pool3 = MaxPooling1D()(drop3)
flat3 = Flatten()(pool3)
# merge the results
merged = concatenate([flat1, flat2, flat3])
# fully connected layer and a sigmoid
dense1 = Dense(20, activation='relu')(merged)
output = Dense(1, activation='sigmoid')(dense1)
#create model
model = Model(inputs=[input1, input2, input3], outputs=[output])
#compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
plot_model(model)
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 1289)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, 1289)] 0
__________________________________________________________________________________________________
input_3 (InputLayer) [(None, 1289)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, 1289, 100) 2354900 input_1[0][0]
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 1289, 100) 2354900 input_2[0][0]
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 1289, 100) 2354900 input_3[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 1286, 32) 12832 embedding[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 1284, 32) 19232 embedding_1[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 1282, 32) 25632 embedding_2[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 1286, 32) 0 conv1d[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 1284, 32) 0 conv1d_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 1282, 32) 0 conv1d_2[0][0]
__________________________________________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 643, 32) 0 dropout[0][0]
__________________________________________________________________________________________________
max_pooling1d_1 (MaxPooling1D) (None, 642, 32) 0 dropout_1[0][0]
__________________________________________________________________________________________________
max_pooling1d_2 (MaxPooling1D) (None, 641, 32) 0 dropout_2[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 20576) 0 max_pooling1d[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 20544) 0 max_pooling1d_1[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 20512) 0 max_pooling1d_2[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 61632) 0 flatten[0][0]
flatten_1[0][0]
flatten_2[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 20) 1232660 concatenate[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 21 dense[0][0]
==================================================================================================
Total params: 8,355,077
Trainable params: 8,355,077
Non-trainable params: 0
__________________________________________________________________________________________________
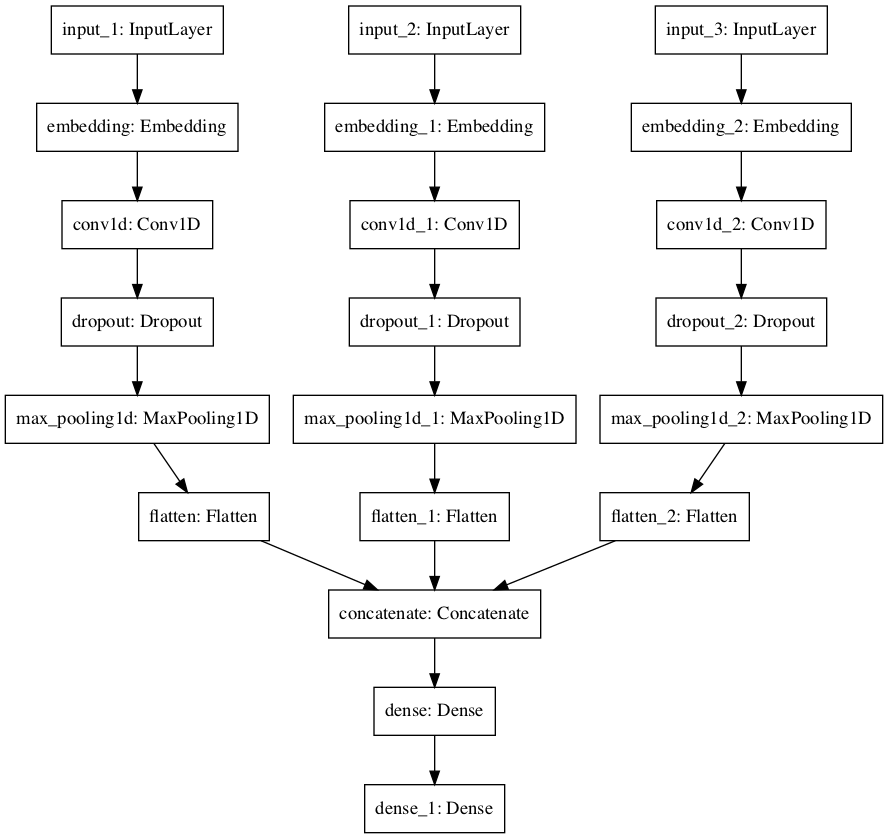
Test model
trainX = transformed['trainX']
trainY = transformed['trainY']
testX = transformed['testX']
testY = transformed['testY']
# create Tensorboard callback
log_dir = 'logs/fit/' + datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
tb_callback = tk.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
H = model.fit([trainX, trainX, trainX], trainY,
validation_data=([testX, testX, testX], testY),
epochs=5,
batch_size=32,
callbacks=[tb_callback])
Train on 1800 samples, validate on 200 samples
Epoch 1/5
1800/1800 [==============================] - 78s 43ms/sample - loss: 0.6935 - accuracy: 0.5428 - val_loss: 0.6858 - val_accuracy: 0.5300
Epoch 2/5
1800/1800 [==============================] - 64s 35ms/sample - loss: 0.4144 - accuracy: 0.8567 - val_loss: 0.3701 - val_accuracy: 0.8600
Epoch 3/5
1800/1800 [==============================] - 61s 34ms/sample - loss: 0.0373 - accuracy: 0.9878 - val_loss: 0.4074 - val_accuracy: 0.8250
Epoch 4/5
1800/1800 [==============================] - 65s 36ms/sample - loss: 0.0037 - accuracy: 0.9994 - val_loss: 0.3647 - val_accuracy: 0.8750
Epoch 5/5
1800/1800 [==============================] - 65s 36ms/sample - loss: 0.0017 - accuracy: 0.9994 - val_loss: 0.3661 - val_accuracy: 0.8900
predictions = model.predict([testX, testX, testX], batch_size=32)
print(classification_report(testY, np.rint(predictions), target_names=['neg','pos']))
precision recall f1-score support
neg 0.86 0.93 0.89 100
pos 0.92 0.85 0.89 100
accuracy 0.89 200
macro avg 0.89 0.89 0.89 200
weighted avg 0.89 0.89 0.89 200
Test against two real reviews
This model passes the win condition with a validation accuracy of 89%. Let’s see if it passes the eye test with some real reviews.
def pos_or_neg(filename, vocab_set, model, tokenizer):
test = []
test.append(doc_to_line(filename, vocab_set))
test = tokenizer.texts_to_sequences(test)
test = pad_sequences(test, max_length)
p = model.predict([test,test,test])[0][0]
if round(p) == 0:
print('This was a negative review with probability:', round((1-p)*100,2),'%')
elif round(p) == 1:
print('This was a positive review with probability:', round((p)*100,2),'%')
The first test is a negative review of the new star wars movie, giving it 1/5 stars.
pos_or_neg('negative_star_wars_review.txt', vocab_set, model, tokenizer)
This was a positive review with probability: 70.0 %
The second test is a positive review of the new star wars moving giving it 3.5/4 stars.
pos_or_neg('positive_star_wars_review.txt', vocab_set, model, tokenizer)
This was a positive review with probability: 99.66 %
Not an ideal performance on the eye test here but at least does very well on the positive review. I’ll try another negative review just to see.
Here’s another negative review of Star Wars. This one is longer and that might help the scoring (as there will be less padding).
pos_or_neg('negative_star_wars_review2.txt', vocab_set, model, tokenizer)
This was a positive review with probability: 99.02 %
Ouch… upon reading the review, it is more verbose and complicated than the average review is likely to be. Well we’ve definitely discovered some limitations of this model.