Implementing Convolutional Neural Network
This notebook is an implementation of a convolutional neural network with forward and back propogation using no machine learning libraries. I will implement one convolution layer, one activation layer, one pooling layer, one fully connected layer producing logits, and then a softmax.

Data from mnist, thanks to Yann LeCun, Corinna Cortes, Christopher J.C. Burges. Using mnist python module to simplify data processing.
Thanks to Victor Zhou and the Coursera Convolution Course for help with this implementation.
Import Libraries and Data
import numpy as np
import mnist
import scipy.misc
import random
random.seed(1)
X_train = mnist.train_images()
y_train = mnist.train_labels()
X_test = mnist.test_images()
y_test = mnist.test_labels()
scipy.misc.toimage(scipy.misc.imresize(X_train[0,:,:] * -1 + 256, 10.))
/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:5: DeprecationWarning: `imresize` is deprecated!
`imresize` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0.
Use ``skimage.transform.resize`` instead.
"""
/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:5: DeprecationWarning: `toimage` is deprecated!
`toimage` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0.
Use Pillow's ``Image.fromarray`` directly instead.
"""
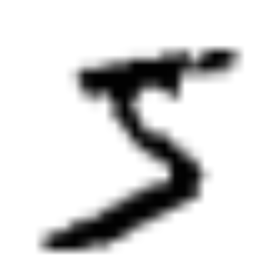
Forward Propogation
All hyperparameters hardcoded: 3X3 convolution filters, 8 convolution filters, stride 1 convolution, valid padding, 2X2 max pooling with stride 2.
def normalize_images(X):
return (X/255) -0.5
def initialize_parameters():
np.random.seed(1)
convW = np.random.randn(3,3,8)/3
convb = np.zeros(8)
logitsW = np.random.randn(1352, 10)/135
logitsb = np.zeros(10)
print('parameters initialized.')
return convW, convb, logitsW, logitsb
def conv_slice(x_slice, W, bias):
return np.sum(np.multiply(x_slice, W)) + float(bias)
def convolve(X, W, b):
(m, nHi, nWi) = X.shape
(f, f, nCo) = W.shape
nHo = int(nHi - f + 1)
nWo = int(nWi - f + 1)
Z = np.zeros((m, nHo, nWo, nCo))
for i in range(m):
x = X[i,:,:]
z = Z[i,:,:,:]
for h in range(nHo):
for w in range(nWo):
for c in range(nCo):
x_slice = x[h:h+f, w:w+f]
z[h,w,c] = conv_slice(x_slice, W[:,:,c], b[c])
Z[i,:,:,:] = z
cache = (W,b)
return Z, cache
def relu(Z):
A = Z*(Z>0)
return A
def max_pool2(A):
(m, nHi, nWi, nCi) = A.shape
nHo = int((nHi-2)/2 + 1)
nWo = int((nWi-2)/2 + 1)
nCo = nCi
P = np.zeros((m, nHo, nWo, nCo))
for i in range(m):
a = A[i,:,:,:]
p = P[i,:,:,:]
for h in range(nHo):
for w in range(nWo):
for c in range(nCo):
a_slice = a[h*2:h*2+2, w*2:w*2+2, c]
p[h,w,c] = np.max(a_slice)
P[i,:,:,:] = p
return P
def perceptron(f, W, b):
return np.dot(f, W) + b
def logit(P, W, b):
init_shape = P.shape
(m, nHi, nWi, nCi) = init_shape
F = P.reshape(m, nHi*nWi*nCi)
logits = np.apply_along_axis(perceptron, 1, F, W, b)
cache = (W, b, init_shape)
return logits, cache
def softmax_single(row):
exp = np.exp(row)
return exp/np.sum(exp)
def softmax(logits):
return np.apply_along_axis(softmax_single, 1, logits)
def forward_prop(X, convW, convb, logitsW, logitsb):
Z, cache_conv = convolve(X, convW, convb)
print('conv done.')
A = relu(Z)
print('activation done.')
P = max_pool2(A)
print('max pooling done.')
logits, cache_logits = logit(P, logitsW, logitsb)
print('multilayer perceptron done.')
out = softmax(logits)
print('softmax done.')
cache_total = (logits, cache_logits, P, A, Z, cache_conv)
return out, cache_total
def evaluate(out, y):
m = len(y)
prob = np.amax(out, axis=1)
pred = np.argmax(out, axis=1)
right_pred = (pred==y)
acc = np.mean(right_pred)*100
loss = - np.log(out[range(m), y])
avg_loss = np.mean(loss)
return acc, avg_loss
X_train_norm_20 = normalize_images(X_train[:20])
y_train_20 = y_train[:20]
print('starting.')
convW, convb, logitsW, logitsb = initialize_parameters()
out, cache_total = forward_prop(X_train_norm_20, convW, convb, logitsW, logitsb)
starting.
parameters initialized.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
acc, avg_loss = evaluate(out, y_train_20)
print(f'Accuracy:{acc:.2f}, Avg Loss: {avg_loss:.5f}')
Accuracy:15.00, Avg Loss: 2.31577
Back Propagation
Using ∂L/∂oi=pi−yi as derived here.
def softmax_backprop(out, y):
m = len(y)
grad = out - np.asarray([[(1 if i==element else 0) for i in range(10)] for element in y])
delta_logits = grad/m
return delta_logits
Using: 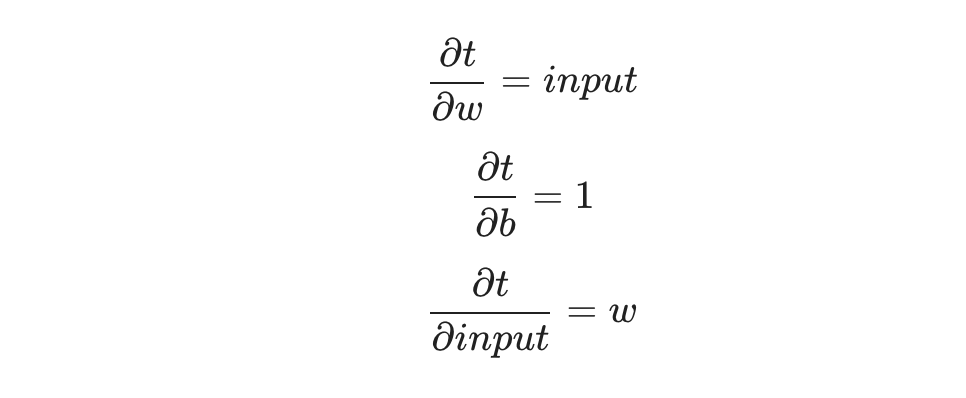
def logits_backprop(delta_logits, cache_logits, P, learning_rate):
(W, b, init_shape) = cache_logits
(m, nHi, nWi, nCi) = init_shape
F = P.reshape(m, nHi*nWi*nCi)
delta_W = np.zeros(W.shape)
delta_b = np.zeros(b.shape)
delta_F = np.zeros(F.shape)
for i in range(m):
delta_W += F[i,:][:,None]@delta_logits[i,:][None,:]
delta_b += delta_logits[i,:]
delta_F[i,:]+= W.dot(delta_logits[i,:])
delta_P = delta_F.reshape(init_shape)
new_W = W - delta_W * learning_rate
new_b = b - delta_b * learning_rate
return delta_P, new_W, new_b
def get_max_mask(a_slice):
return np.max(a_slice)
def max_pooling_backprop(delta_P, A):
(m, nHi, nWi, nCi) = delta_P.shape
delta_A = np.zeros(A.shape)
for i in range(m):
delta_p = delta_P[i,:,:,:]
delta_a = delta_A[i,:,:,:]
a = A[i,:,:,:]
for h in range(nHi):
for w in range(nWi):
for c in range(nCi):
a_slice = a[h*2:h*2+2, w*2:w*2+2, c]
max_mask = get_max_mask(a_slice)
delta_a[h*2:h*2+2, w*2:w*2+2, c] += max_mask*delta_p[h,w,c]
delta_A[i,:,:,:] = delta_a
return delta_A
def relu_backprop(delta_A, Z):
delta_Z = delta_A*(Z>0)
return delta_Z
def conv_backprop(delta_Z, X, cache_conv, learning_rate):
(W,b) = cache_conv
(f, f, nCi) = W.shape
(m, nHo, nWo, nCo) = delta_Z.shape
delta_W = np.zeros(W.shape)
delta_b = np.zeros(b.shape)
for i in range(m):
delta_z = delta_Z[i,:,:,:]
x = X[i,:,:]
for h in range(nHo):
for w in range(nWo):
for c in range(nCo):
delta_W[:,:,c] += x[h:h+f, w:w+f] * delta_Z[i,h,w,c]
delta_b[c] += delta_Z[i,h,w,c]
new_W = W - delta_W*learning_rate
new_b = b - delta_b*learning_rate
return new_W, new_b
def backward_prop(X, y, out, cache_total, learning_rate):
(logits, cache_logits, P, A, Z, cache_conv) = cache_total
delta_logits = softmax_backprop(out, y)
print('softmax_backprop done.')
delta_P, new_logitsW, new_logitsb = logits_backprop(delta_logits, cache_logits, P, learning_rate)
print('neural net backprop done.')
delta_A = max_pooling_backprop(delta_P, A)
print('max_pooling_backprop done.')
delta_Z = relu_backprop(delta_A, Z)
print('relu_backprop done.')
new_convW, new_convb = conv_backprop(delta_Z, X, cache_conv, learning_rate)
print('conv_backprop done.')
return new_convW, new_convb, new_logitsW, new_logitsb
_,_,_,_ = backward_prop(X_train_norm_20, y_train_20, out, cache_total, learning_rate=0.1)
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
Implement training function
def train_cnn(X, y, init_convW, init_convb, init_logitsW, init_logitsb, epochs=5, learning_rate = 0.0002):
convW, convb, logitsW, logitsb = init_convW, init_convb, init_logitsW, init_logitsb
for i in range(epochs):
out, cache_total = forward_prop(X, convW, convb, logitsW, logitsb)
acc, avg_loss = evaluate(out, y)
print(f'Epoch {i} \n Accuracy:{acc:.2f}, Avg Loss: {avg_loss:.5f} \n --- \n')
#print(out[range(len(y)), y])
convW, convb, logitsW, logitsb = backward_prop(X, y, out, cache_total, learning_rate)
out, cache_total = forward_prop(X, convW, convb, logitsW, logitsb)
acc, avg_loss = evaluate(out, y)
print(f'Epoch {epochs} \n Accuracy:{acc:.2f}, Avg Loss: {avg_loss:.5f} \n --- \n')
return out, cache_total, acc, avg_loss
sample_size = 100
epochs = 5
learning_rate = .1
X_train_norm_sample = normalize_images(X_train[:sample_size])
y_train_sample = y_train[:sample_size]
convW, convb, logitsW, logitsb = initialize_parameters()
out, cache_total, acc, avg_loss = train_cnn(X_train_norm_sample, y_train_sample, convW, convb, logitsW, logitsb, epochs=epochs, learning_rate=learning_rate)
parameters initialized.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 0
Accuracy:17.00, Avg Loss: 2.30219
---
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 1
Accuracy:41.00, Avg Loss: 2.10387
---
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 2
Accuracy:58.00, Avg Loss: 1.94948
---
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 3
Accuracy:75.00, Avg Loss: 1.79744
---
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 4
Accuracy:80.00, Avg Loss: 1.64556
---
softmax_backprop done.
neural net backprop done.
max_pooling_backprop done.
relu_backprop done.
conv_backprop done.
conv done.
activation done.
max pooling done.
multilayer perceptron done.
softmax done.
Epoch 5
Accuracy:83.00, Avg Loss: 1.48968
---